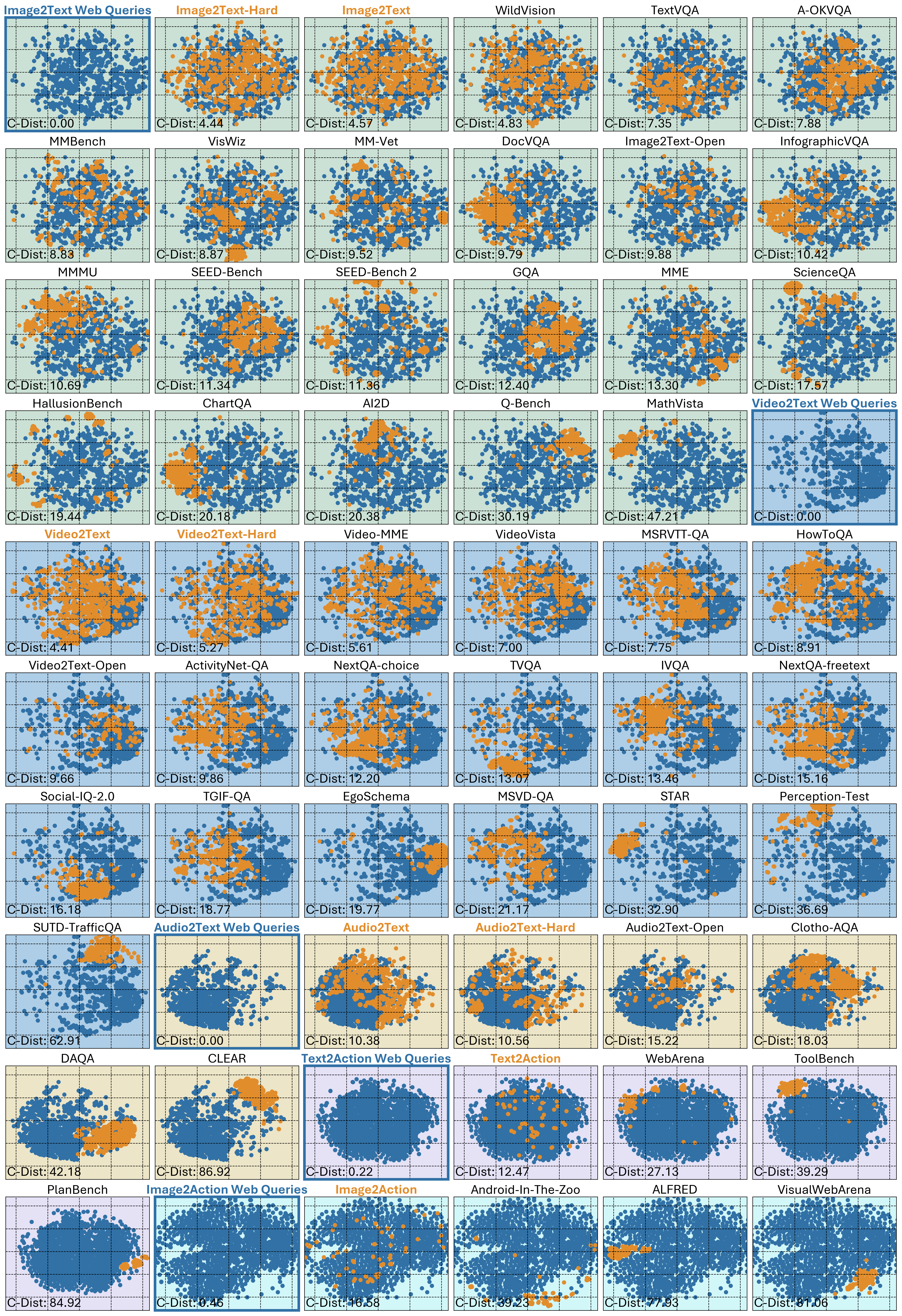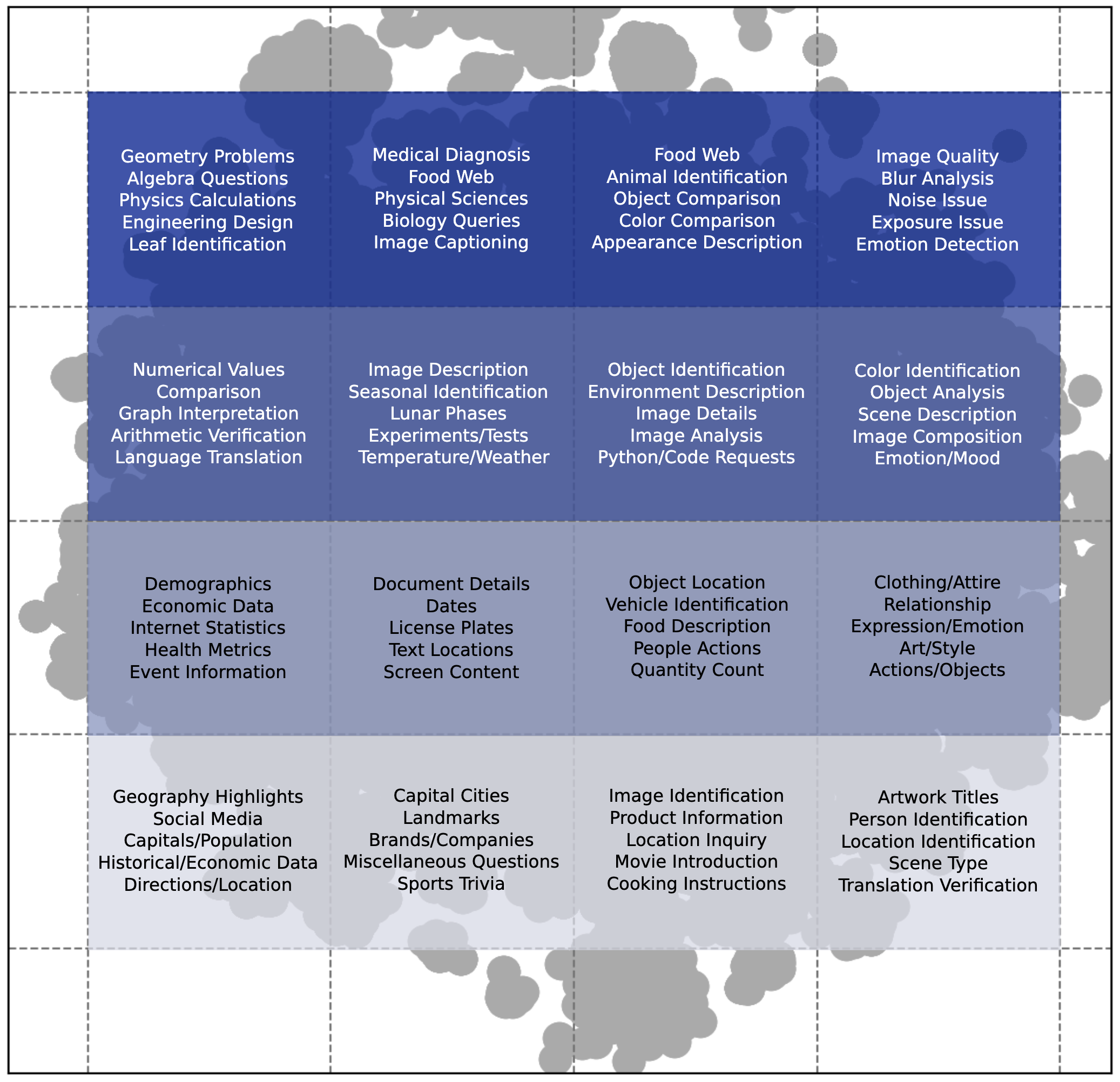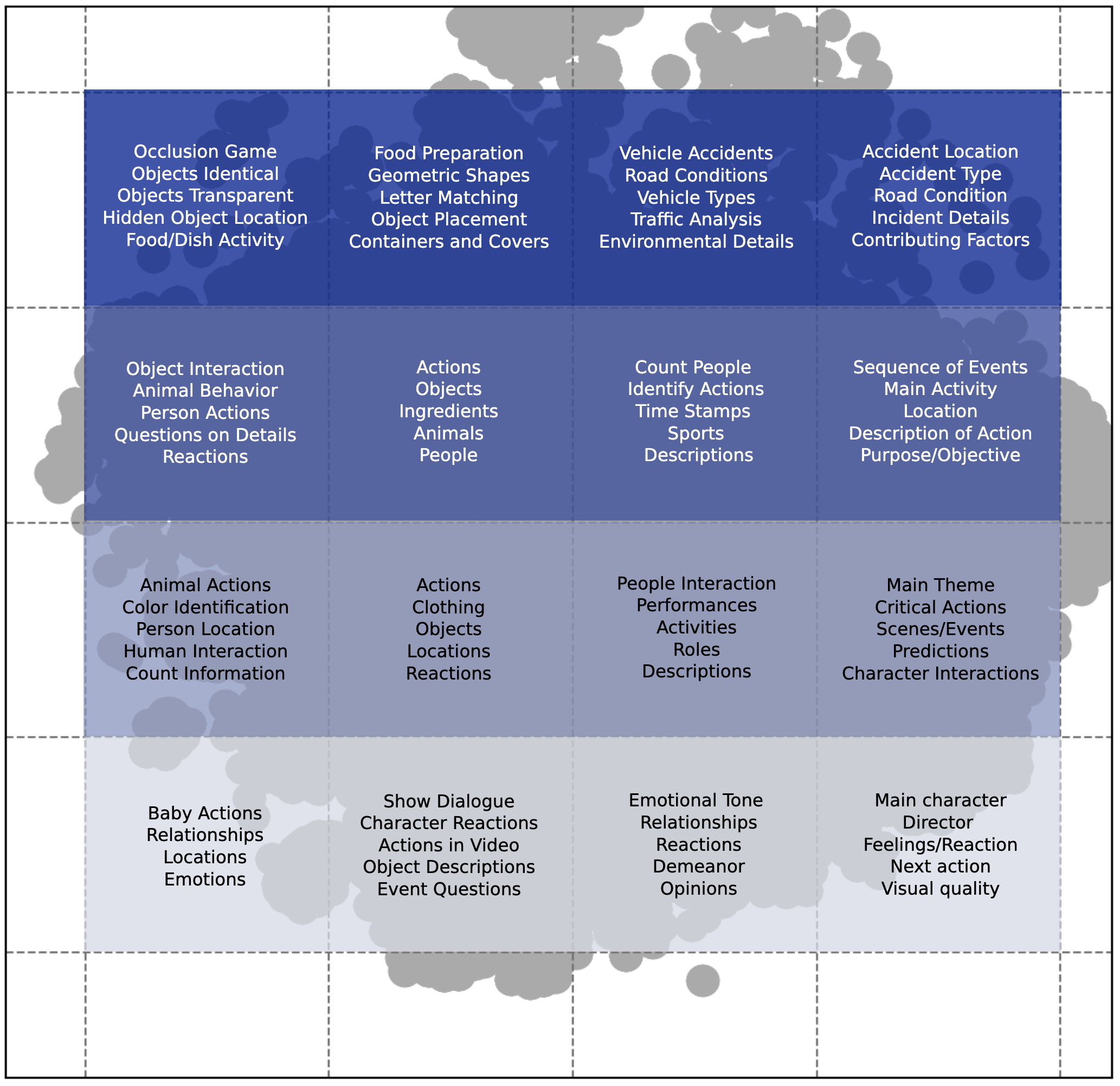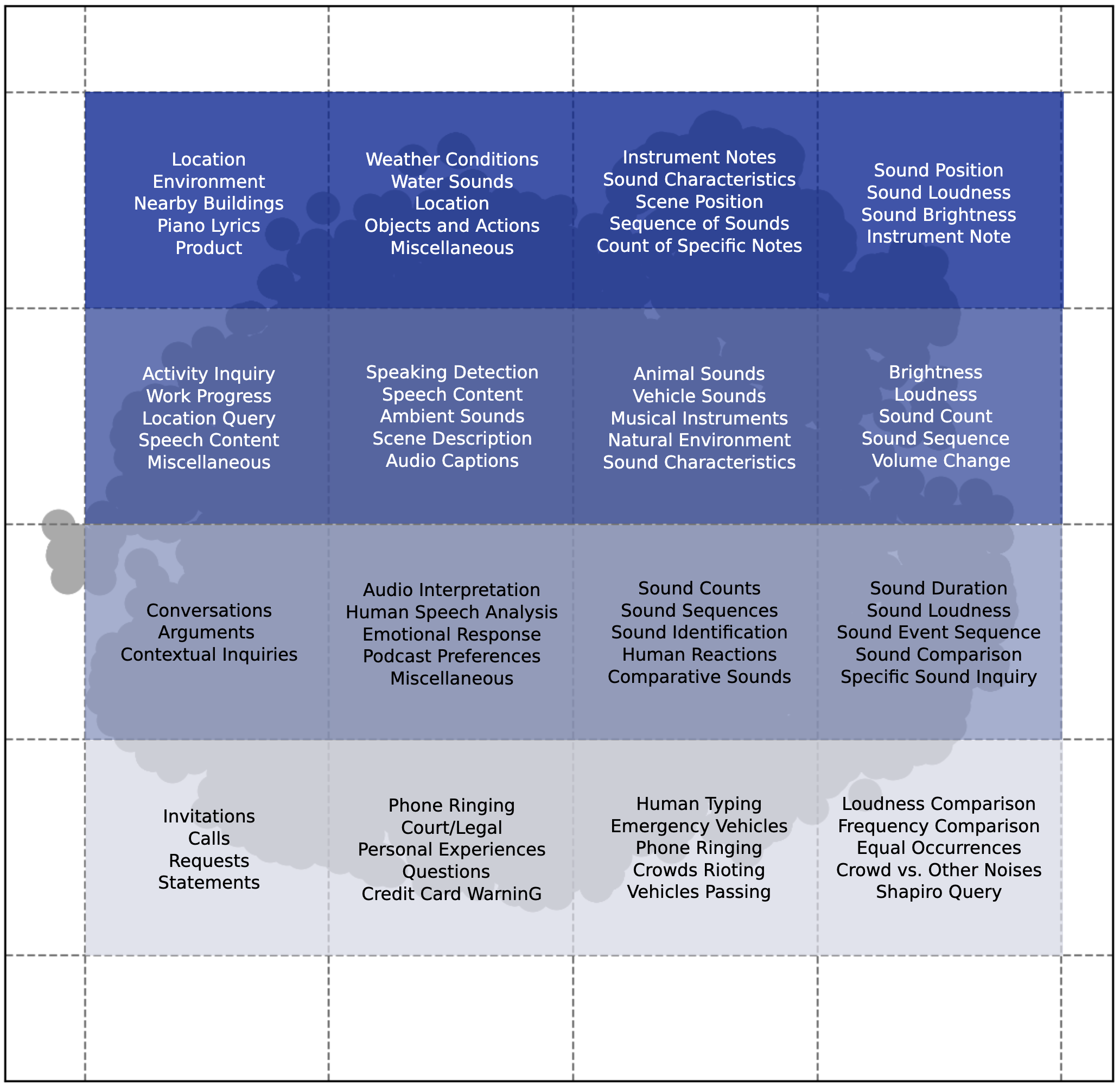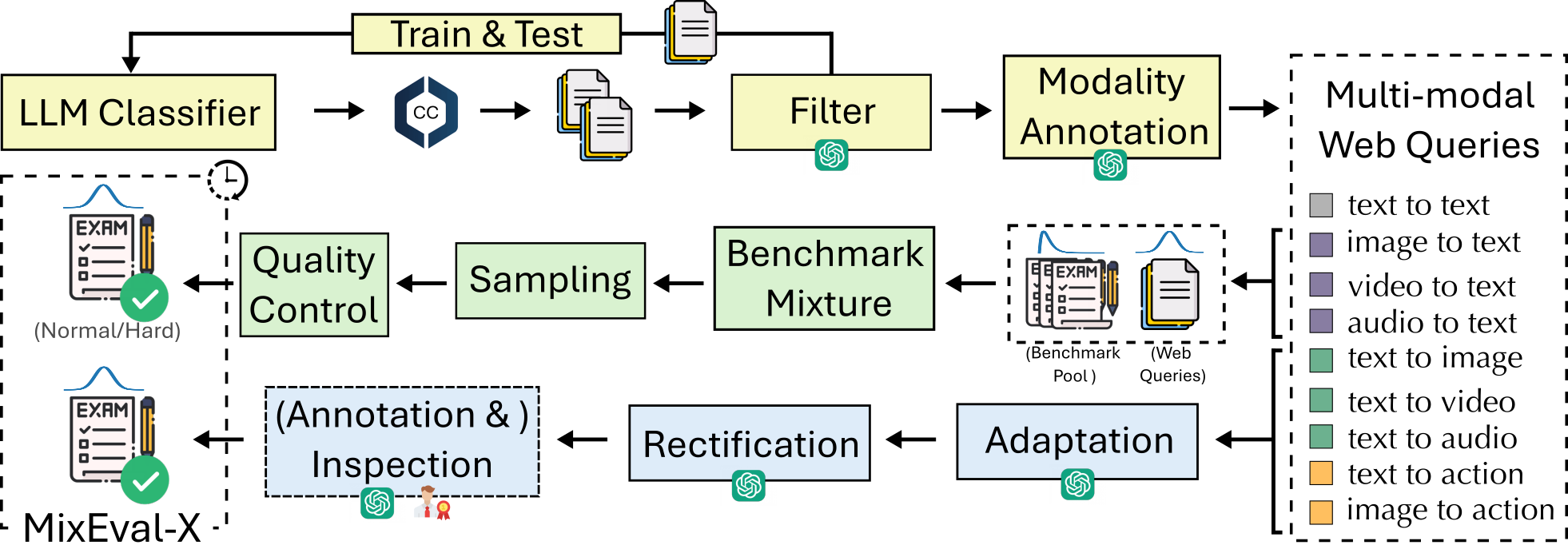
🌆
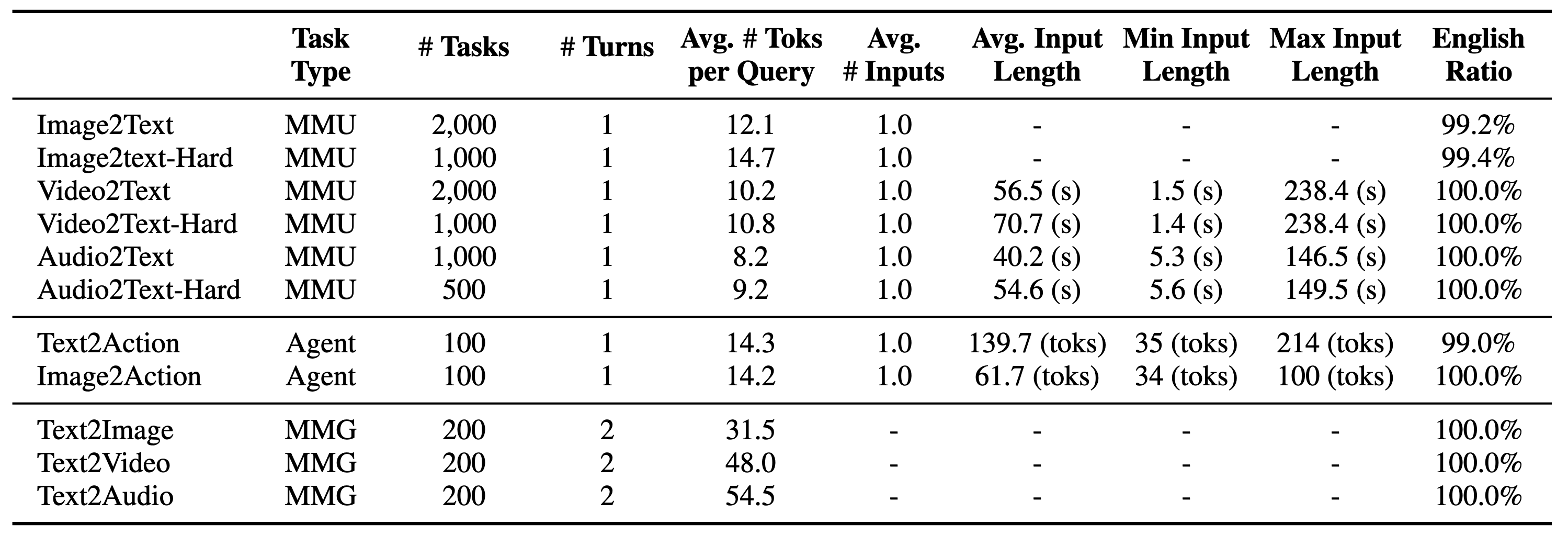
Image2Text📽️
Video2Text🎧
Audio2Text🌆
Text2Image📽️
Text2Video🎧
Text2Audio🧑🦯
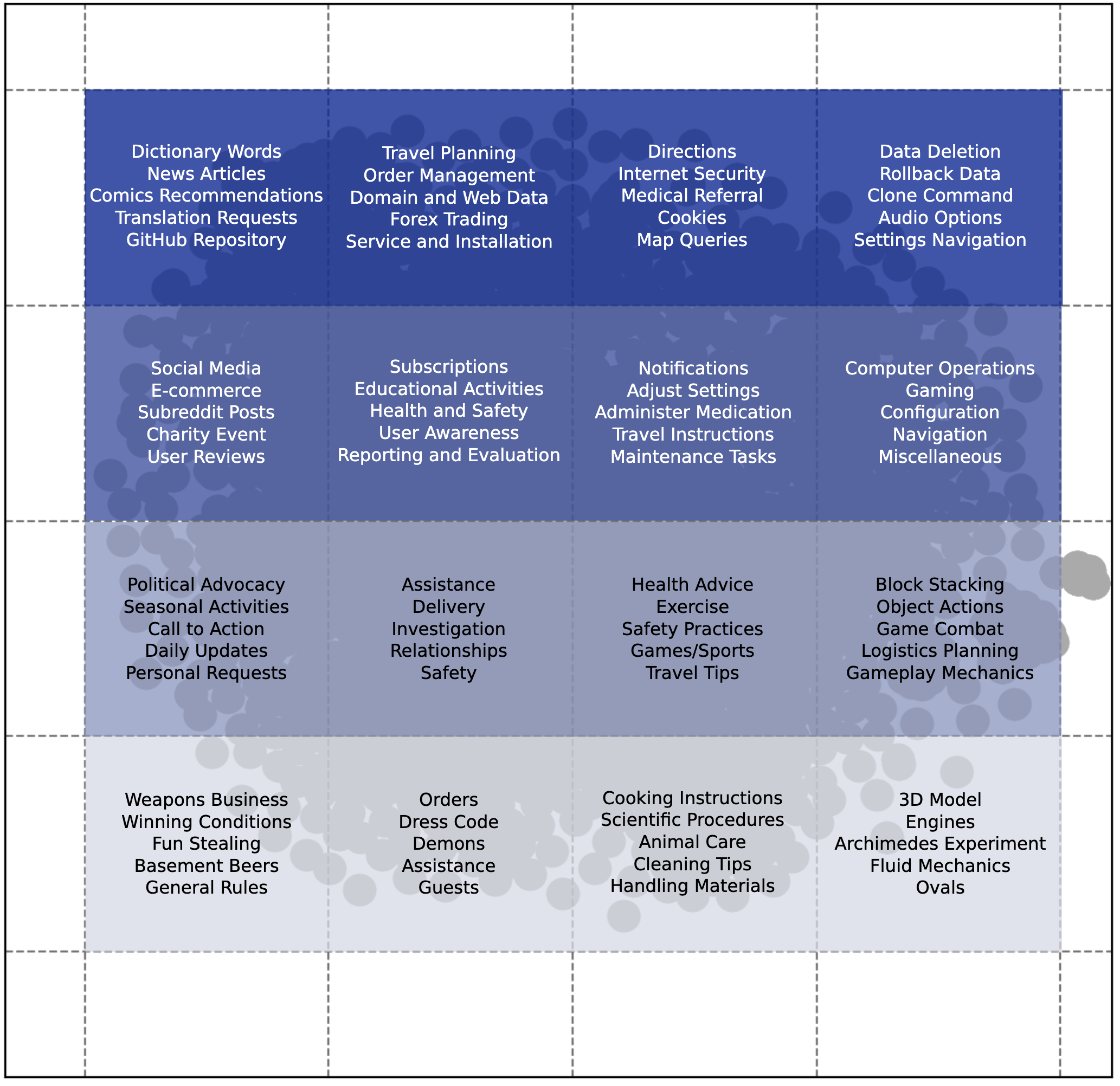
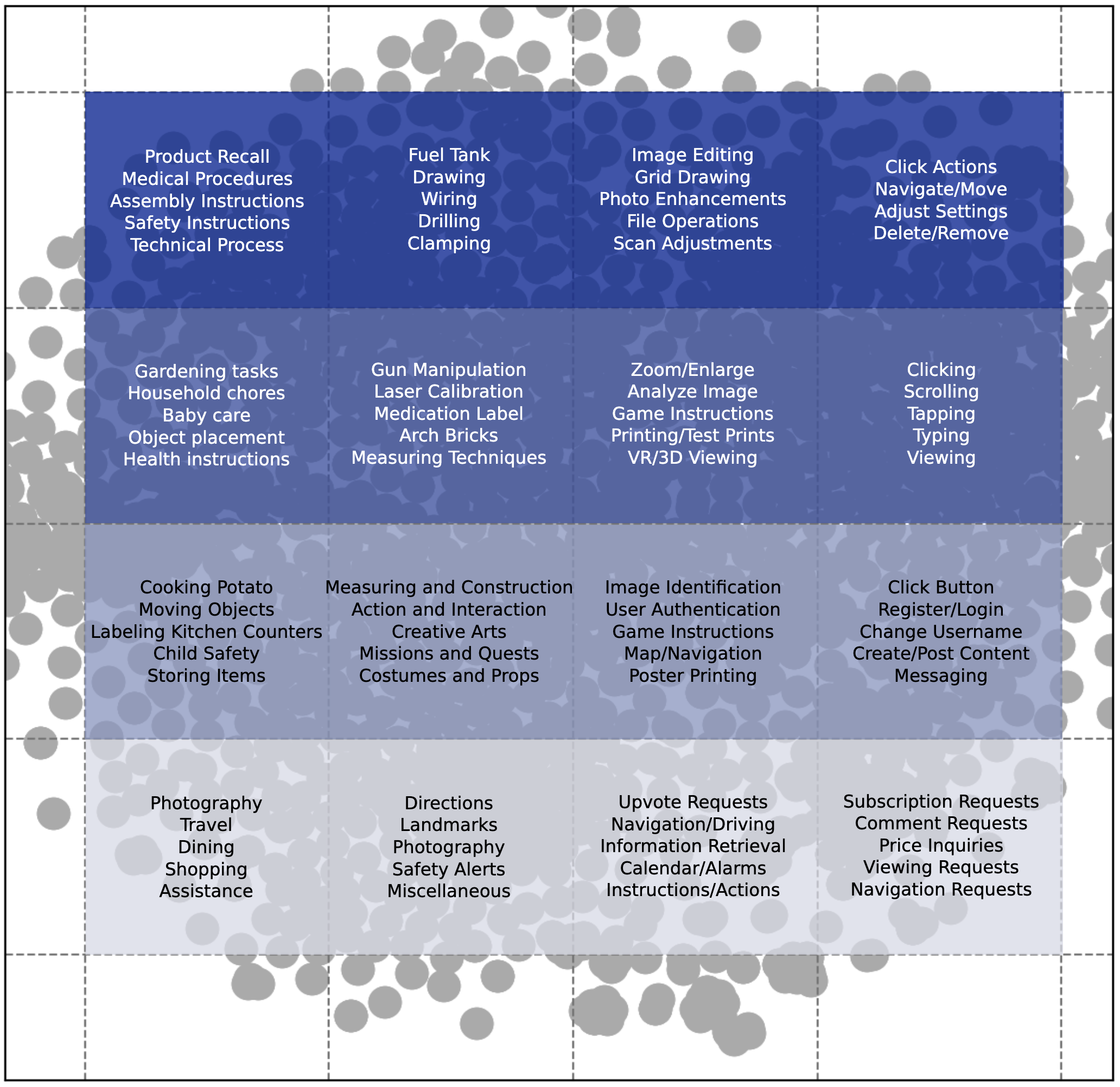
Text2Action🚶
Image2ActionMixEval-X Image2Text Leaderboard
Open-Source
Proprietary
| Image2Text 🥇 |
Image2Text-Hard 🥇 |
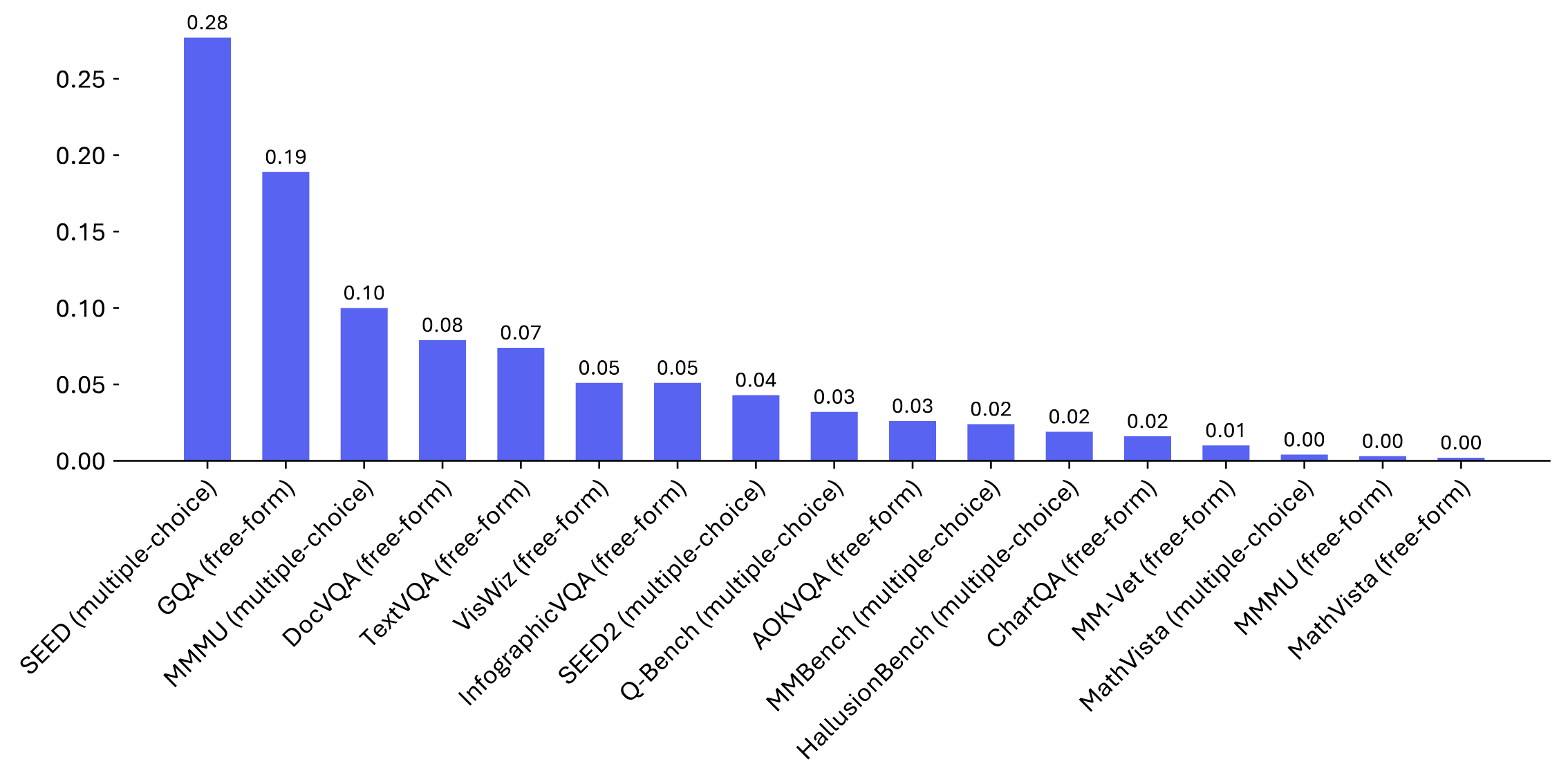
SEED (Mixed) |
MMMU (Mixed) |
DocVQA (Mixed) |
TextVQA (Mixed) |
VisWiz (Mixed) |
InfographicVQA (Mixed) |
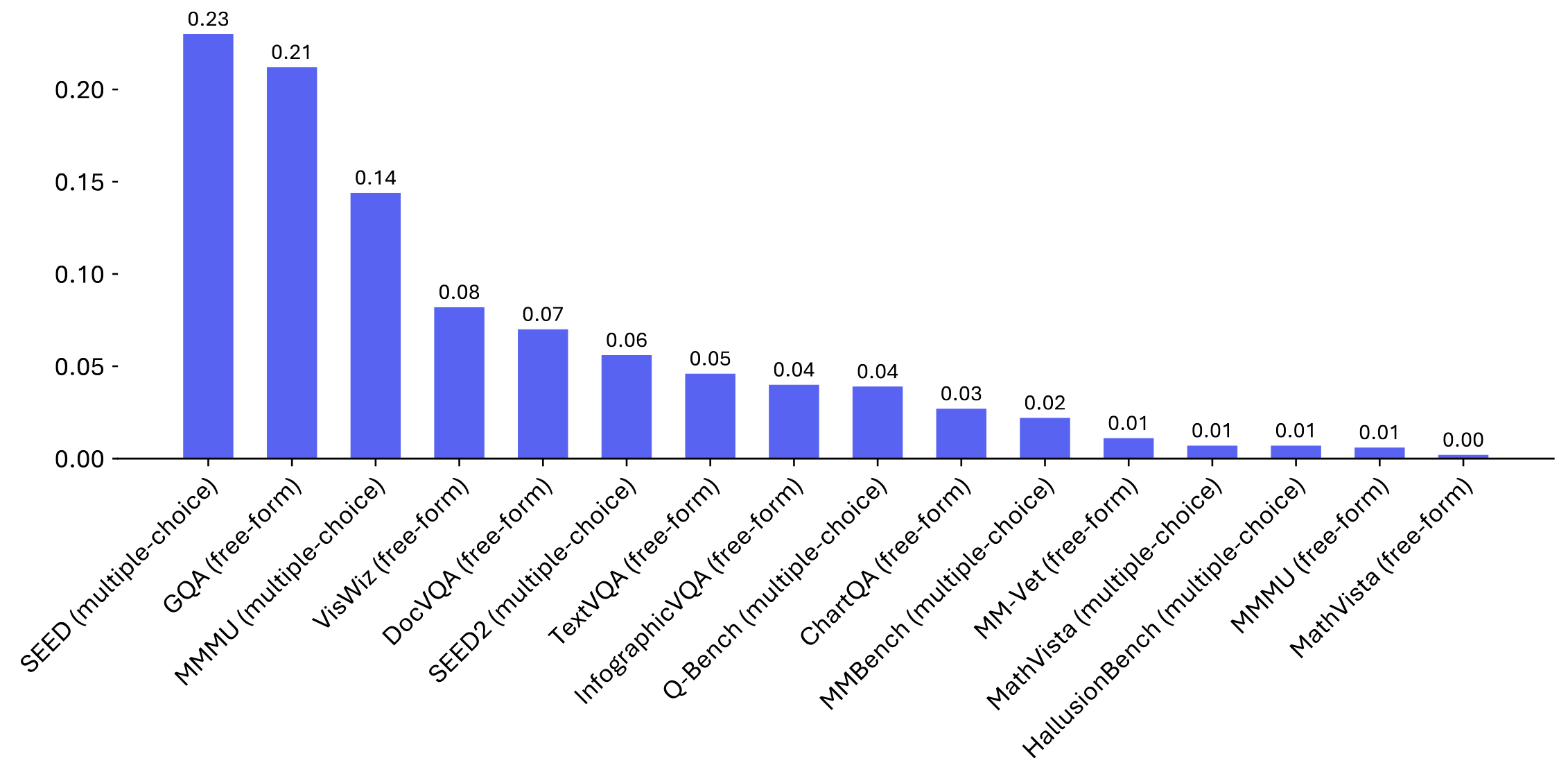
SEED-Hard (Mixed) |
MMMU-Hard (Mixed) |
|
| Claude 3.5 Sonnet | 76.9 | 46.2 | 76.0 | 75.1 | 94.6 | 90.3 | 62.5 | 78.8 | 31.0 | 48.9 |
| GPT-4o | 76.6 | 45.8 | 75.6 | 74.1 | 87.4 | 90.9 | 66.9 | 79.0 | 29.3 | 45.9 |
| GPT-4V | 75.0 | 44.6 | 75.6 | 68.0 | 92.1 | 89.3 | 53.7 | 79.2 | 31.9 | 40.6 |
| Qwen2-VL-72B | 74.8 | 43.4 | 71.5 | 67.5 | 90.6 | 90.3 | 66.3 | 80.4 | 25.4 | 27.8 |
| Gemini 1.5 Pro | 74.2 | 42.2 | 72.2 | 77.2 | 85.6 | 86.8 | 63.7 | 76.7 | 29.7 | 44.4 |
| Llama 3.2 90B | 73.0 | 40.6 | 73.3 | 62.9 | 92.7 | 90.9 | 61.6 | 89.8 | 28.9 | 30.1 |
| InternVL2-26B | 71.5 | 41.5 | 71.5 | 55.8 | 90.3 | 91.2 | 58.2 | 70.2 | 32.3 | 28.6 |
| InternVL-Chat-V1.5 | 70.1 | 37.5 | 70.7 | 56.9 | 83.6 | 83.1 | 55.3 | 61.2 | 22.0 | 18.8 |
| Claude 3 Opus | 69.5 | 41.1 | 72.0 | 66.5 | 84.2 | 86.7 | 56.9 | 66.9 | 34.9 | 44.4 |
| Qwen-VL-MAX | 69.2 | 37.5 | 70.0 | 68.5 | 83.1 | 87.2 | 53.1 | 66.1 | 27.6 | 37.6 |
| LLaVA-1.6-34B | 68.1 | 37.5 | 70.4 | 60.4 | 71.0 | 81.8 | 48.6 | 58.8 | 31.9 | 36.8 |
| Claude 3 Sonnet | 67.8 | 38.3 | 71.1 | 50.8 | 86.7 | 80.3 | 58.2 | 78.6 | 32.3 | 30.8 |
| Reka Core | 67.4 | 37.3 | 67.5 | 71.1 | 76.5 | 79.9 | 56.9 | 59.6 | 25.0 | 39.1 |
| Reka Flash | 67.4 | 36.6 | 73.6 | 53.8 | 71.3 | 76.8 | 59.6 | 62.5 | 32.8 | 23.3 |
| InternVL-Chat-V1.2 | 67.2 | 36.0 | 70.7 | 54.8 | 51.8 | 76.3 | 60.0 | 59.2 | 25.4 | 33.8 |
| Qwen-VL-PLUS | 67.0 | 35.9 | 66.2 | 56.9 | 84.1 | 83.1 | 57.5 | 52.7 | 19.8 | 27.1 |
| Claude 3 Haiku | 66.1 | 37.5 | 67.8 | 58.4 | 88.3 | 83.0 | 59.8 | 59.4 | 32.8 | 45.9 |
| Gemini 1.0 Pro | 66.1 | 35.0 | 67.6 | 60.9 | 70.3 | 81.3 | 55.7 | 51.8 | 29.3 | 39.8 |
| InternLM-XComposer2-VL | 62.1 | 33.6 | 66.9 | 40.6 | 54.7 | 74.9 | 56.3 | 46.5 | 28.9 | 24.8 |
| InternVL-Chat-V1.1 | 58.5 | 30.9 | 68.0 | 46.7 | 38.3 | 64.6 | 52.5 | 37.5 | 28.4 | 30.8 |
| Yi-VL-34B | 58.5 | 30.6 | 68.0 | 53.8 | 21.5 | 59.7 | 53.3 | 41.4 | 27.6 | 29.3 |
| OmniLMM-12B | 58.2 | 29.2 | 67.3 | 54.8 | 42.3 | 70.2 | 48.6 | 26.9 | 31.9 | 32.3 |
| DeepSeek-VL-7B-Chat | 56.7 | 26.5 | 61.3 | 41.1 | 39.4 | 69.9 | 50.8 | 32.0 | 21.1 | 14.3 |
| Yi-VL-6B | 55.4 | 30.1 | 65.6 | 45.7 | 23.6 | 62.3 | 52.2 | 28.0 | 27.6 | 19.5 |
| InfiMM-Zephyr-7B | 53.7 | 29.4 | 62.5 | 44.2 | 21.9 | 46.1 | 46.1 | 27.6 | 26.7 | 25.6 |
| CogVLM | 51.5 | 23.7 | 54.4 | 25.4 | 46.4 | 70.5 | 46.5 | 56.1 | 21.6 | 11.3 |
| MiniCPM-V | 51.5 | 25.9 | 59.1 | 32.0 | 53.2 | 76.6 | 40.8 | 32.2 | 23.7 | 18.0 |
| Marco-VL | 50.5 | 24.3 | 56.0 | 37.1 | 48.2 | 58.1 | 37.3 | 40.6 | 19.0 | 27.8 |
| LLaVA-1.5-13B | 50.2 | 26.0 | 56.9 | 32.5 | 22.4 | 53.7 | 42.9 | 24.3 | 19.0 | 24.8 |
| SVIT | 49.9 | 25.4 | 59.1 | 35.5 | 19.9 | 51.2 | 42.9 | 27.8 | 27.6 | 15.8 |
| mPLUG-OWL2 | 48.9 | 22.5 | 57.5 | 28.9 | 26.9 | 59.7 | 39.8 | 29.4 | 28.0 | 10.5 |
| SPHINX | 47.5 | 23.8 | 54.5 | 39.1 | 16.4 | 51.0 | 41.4 | 24.5 | 19.8 | 18.0 |
| InstructBLIP-T5-XXL | 46.2 | 21.5 | 58.0 | 31.0 | 11.2 | 41.7 | 44.3 | 24.5 | 19.4 | 28.6 |
| InstructBLIP-T5-XL | 45.5 | 22.9 | 53.1 | 32.0 | 14.5 | 44.5 | 44.5 | 12.9 | 21.1 | 18.8 |
| BLIP-2 FLAN-T5-XXL | 45.2 | 21.6 | 55.1 | 33.0 | 13.5 | 46.3 | 42.2 | 29.6 | 22.8 | 17.3 |
| BLIP-2 FLAN-T5-XL | 43.0 | 20.0 | 52.5 | 33.5 | 16.3 | 40.9 | 39.2 | 9.4 | 23.3 | 11.3 |
| Adept Fuyu-Heavy | 37.4 | 19.4 | 43.5 | 26.4 | 6.9 | 41.1 | 35.5 | 8.2 | 21.6 | 11.3 |
| LLaMA-Adapter2-7B | 36.6 | 20.4 | 42.5 | 32.5 | 15.6 | 23.7 | 44.5 | 25.1 | 18.1 | 14.3 |
| Otter | 34.1 | 18.5 | 42.5 | 31.5 | 5.3 | 17.9 | 21.2 | 21.4 | 23.3 | 9.8 |
| MiniGPT4-Vicuna-13B | 32.1 | 15.8 | 38.2 | 25.4 | 15.4 | 23.4 | 33.7 | 18.4 | 15.5 | 13.5 |
*MixEval-X Video2Text Leaderboard
Open-Source
Proprietary
| Video2Text 🥇 |
Video2Text-Hard 🥇 |
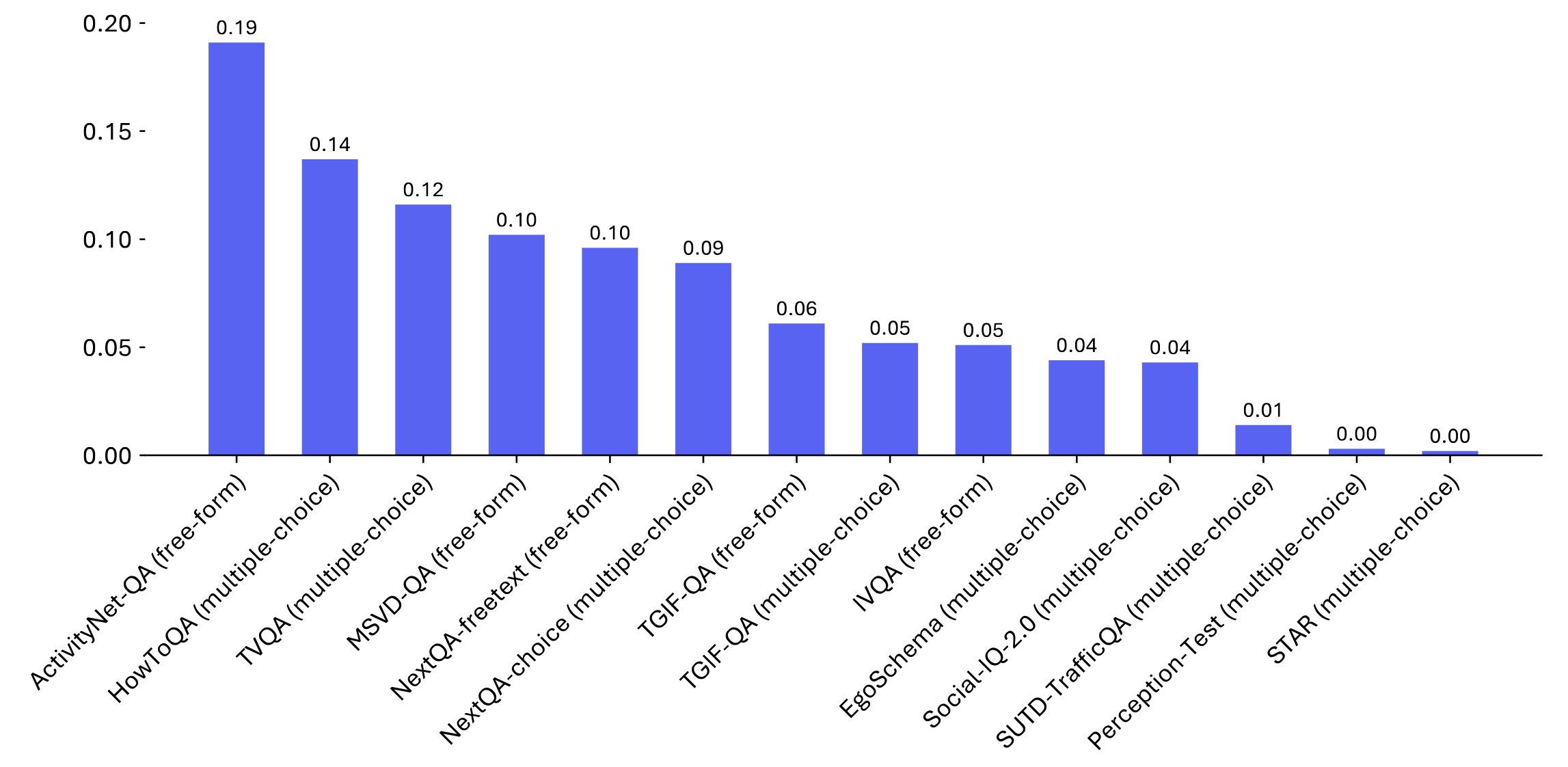
ActivityNet-QA (Mixed) |
HowToQA (Mixed) |
TVQA (Mixed) |
MSVD-QA (Mixed) |
NextQA-freetext (Mixed) |
TGIF-QA (Mixed) |
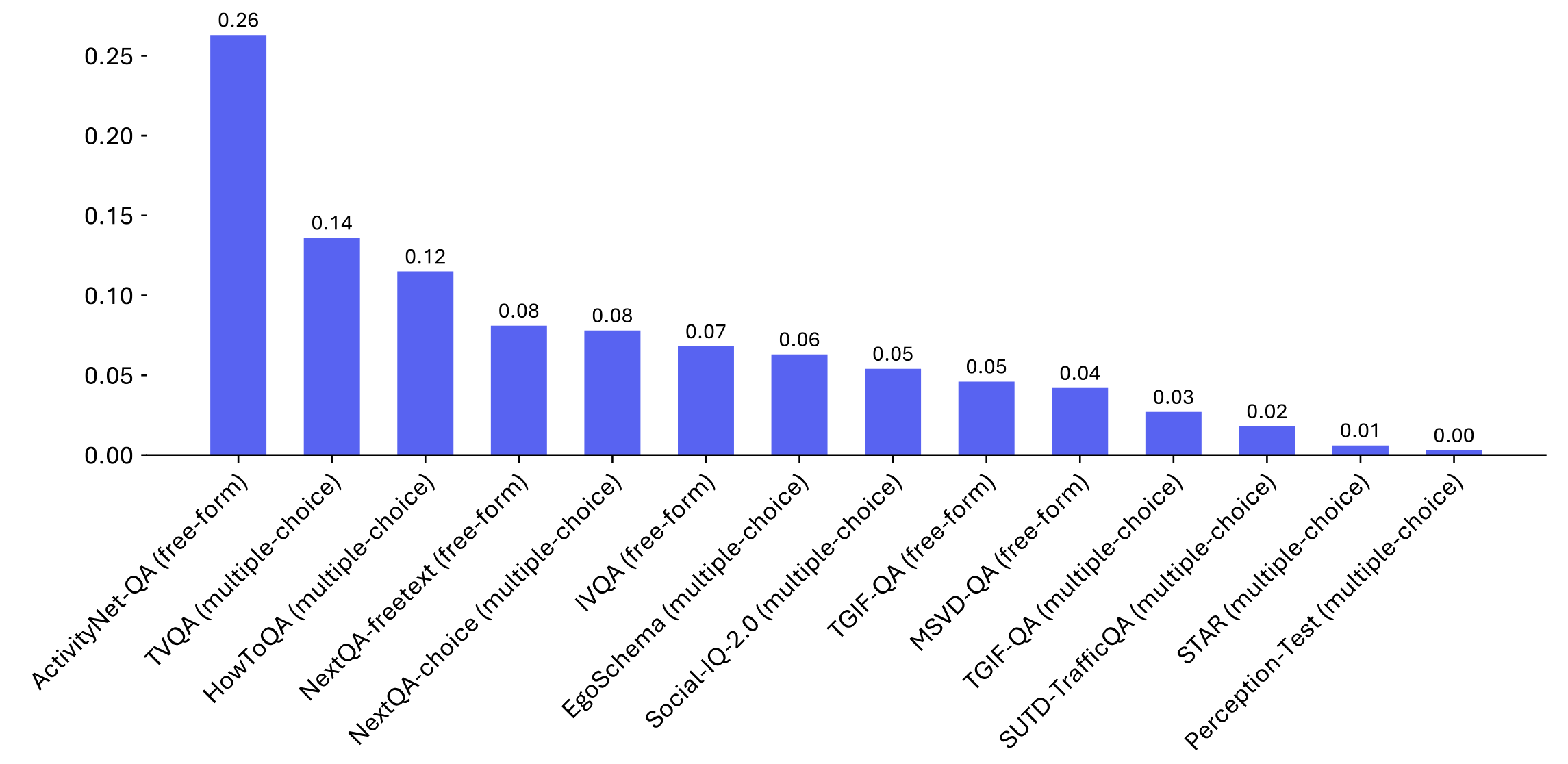
ActivityNet-QA-Hard (Mixed) |
TVQA-Hard (Mixed) |
|
| Claude 3.5 Sonnet | 74.2 | 45.5 | 73.3 | 76.6 | 64.8 | 79.4 | 76.4 | 78.9 | 60.4 | 39.4 |
| GPT-4o | 72.7 | 38.9 | 64.6 | 78.2 | 74.6 | 80.9 | 70.1 | 78.2 | 32.4 | 48.0 |
| Gemini 1.5 Pro | 71.8 | 38.1 | 65.2 | 64.8 | 82.6 | 82.9 | 74.4 | 75.7 | 43.2 | 68.5 |
| GPT-4V | 71.0 | 40.0 | 63.4 | 78.2 | 69.5 | 77.9 | 69.5 | 78.5 | 37.2 | 37.8 |
| Qwen2-VL-72B | 66.5 | 32.0 | 55.1 | 76.6 | 58.1 | 74.2 | 65.0 | 78.5 | 27.3 | 17.3 |
| Gemini 1.5 Flash | 66.3 | 33.9 | 59.0 | 67.4 | 70.3 | 73.8 | 61.4 | 72.3 | 26.7 | 51.2 |
| LLaVA-OneVision-72B-OV | 64.7 | 32.0 | 56.0 | 77.0 | 64.4 | 71.2 | 64.9 | 70.6 | 35.6 | 28.3 |
| Qwen2-VL-7B | 64.2 | 31.9 | 54.3 | 74.7 | 52.1 | 74.9 | 62.6 | 68.9 | 27.2 | 26.0 |
| LLaVA-Next-Video-34B | 63.1 | 28.4 | 56.1 | 68.6 | 62.7 | 74.0 | 62.8 | 68.0 | 26.7 | 38.6 |
| Claude 3 Haiku | 58.7 | 29.4 | 52.3 | 63.6 | 48.7 | 70.8 | 62.7 | 70.2 | 23.6 | 29.1 |
| LLaVA-Next-Video-7B | 58.7 | 27.2 | 53.2 | 62.1 | 44.5 | 72.5 | 61.0 | 74.4 | 25.9 | 33.1 |
| Reka-edge | 58.7 | 27.3 | 51.7 | 72.4 | 46.6 | 69.1 | 59.3 | 65.2 | 29.0 | 22.8 |
| LLaMA-VID | 55.6 | 23.8 | 52.9 | 60.9 | 36.0 | 72.8 | 61.3 | 67.1 | 19.1 | 17.3 |
| VideoLLaVA | 55.3 | 22.6 | 51.7 | 64.0 | 39.4 | 66.7 | 61.9 | 64.7 | 18.2 | 26.0 |
| Video-ChatGPT | 46.4 | 20.7 | 45.7 | 46.7 | 25.4 | 72.2 | 56.3 | 64.8 | 24.7 | 14.2 |
| mPLUG-video | 39.1 | 17.8 | 41.5 | 36.4 | 23.3 | 71.9 | 56.7 | 61.8 | 22.7 | 7.9 |
MixEval-X Audio2Text Leaderboard
Open-Source
Proprietary
| Audio2Text 🥇 |
Audio2Text-Hard 🥇 |
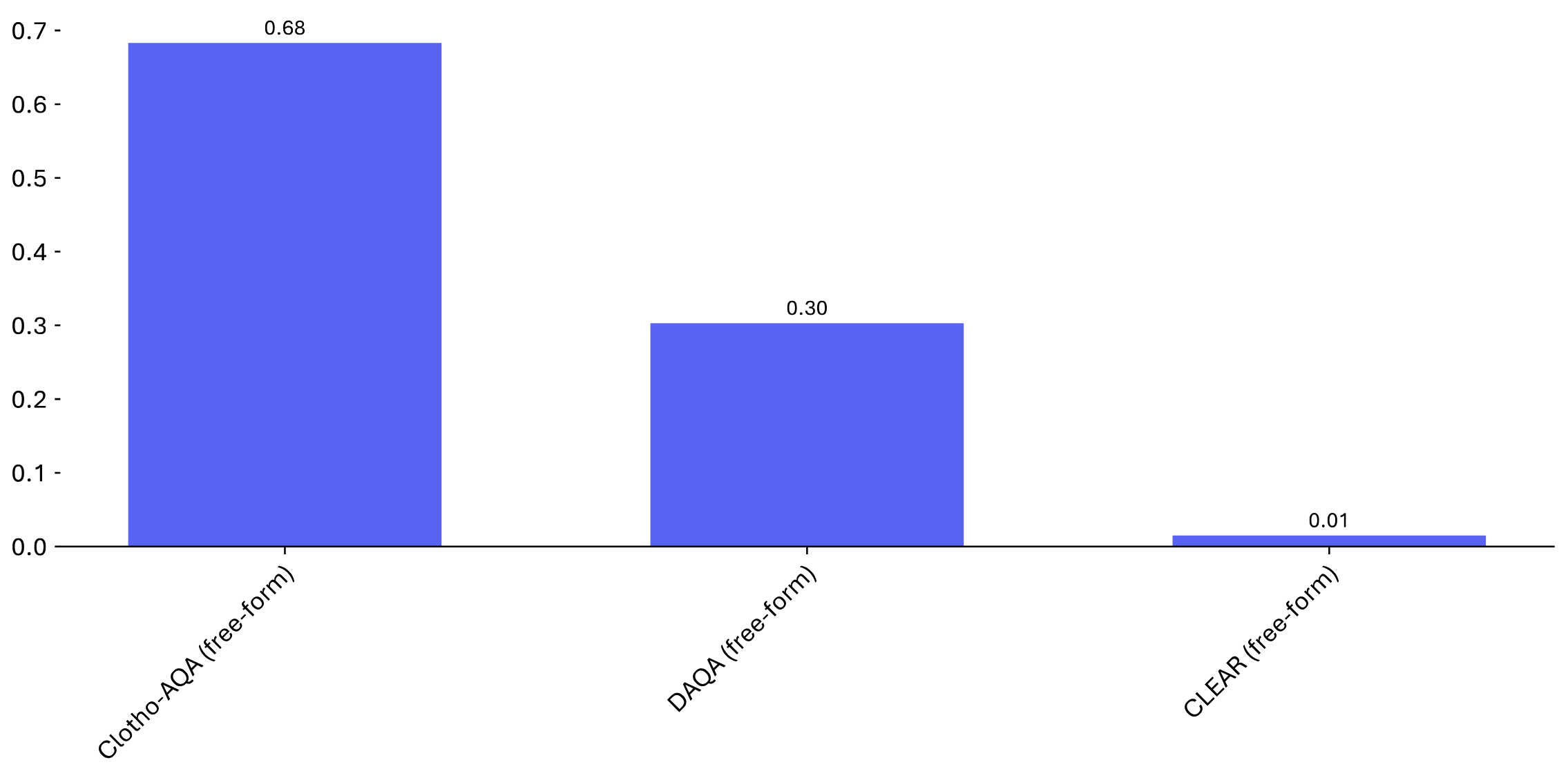
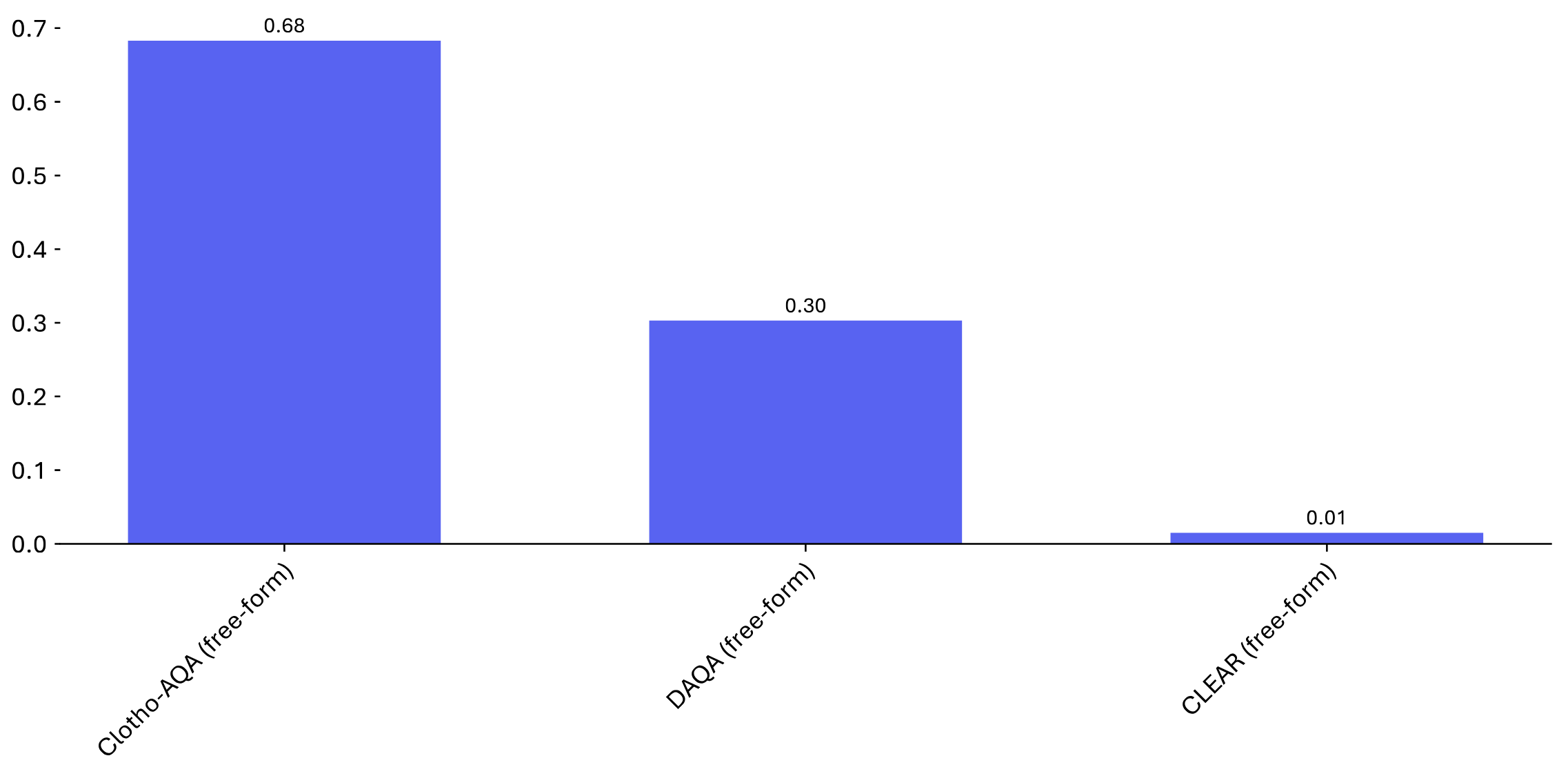
Clotho-AQA (Mixed) |
DAQA (Mixed) |
Clotho-AQA-Hard (Mixed) |
DAQA-Hard (Mixed) |
|
| Gemini 1.5 Pro | 62.7 | 24.0 | 67.4 | 53.4 | 26.8 | 21.7 |
| Gemini 1.5 Flash | 60.1 | 23.0 | 67.1 | 46.9 | 27.4 | 19.7 |
| Qwen2-Audio-7B-Instruct | 58.8 | 23.5 | 64.7 | 46.0 | 22.5 | 23.5 |
| Qwen2-Audio-7B | 56.6 | 24.6 | 63.1 | 44.0 | 29.9 | 20.0 |
| SALMONN-13B | 52.5 | 20.9 | 57.6 | 41.4 | 14.9 | 25.4 |
| Qwen-Audio | 52.4 | 16.0 | 61.5 | 33.8 | 19.0 | 12.8 |
| Qwen-Audio-Chat | 50.2 | 20.0 | 55.7 | 39.4 | 19.8 | 19.7 |
| SALMONN-7B | 38.9 | 17.1 | 46.6 | 22.2 | 20.6 | 11.6 |
| Pengi | 22.6 | 8.2 | 26.9 | 14.4 | 12.5 | 3.8 |
MixEval-X Text2Image Leaderboard
Open-Source
Proprietary
| Text2Image Elo 🥇 |
95% CI | Text2Image Elo (1st Turn) 🥇 |
95% CI (1st Turn) | Text2Image Elo (2nd Turn) 🥇 |
95% CI (2nd Turn) | |
| Flux | 1054 | -11/15 | 1054 | -20/20 | 1058 | -15/21 |
| DALL·E 3 HD | 1047 | -11/12 | 1062 | -19/19 | 1031 | -17/24 |
| PixArtAlpha | 1037 | -15/14 | 1031 | -18/21 | 1041 | -17/16 |
| PlayGround V2.5 | 1027 | -12/14 | 1027 | -20/26 | 1030 | -24/16 |
| PlayGround V2 | 1023 | -13/12 | 1021 | -22/17 | 1022 | -16/19 |
| SD3 | 993 | -18/12 | 986 | -18/18 | 998 | -18/17 |
| Stable Cascade | 961 | -13/15 | 968 | -24/18 | 956 | -19/25 |
| SD1.5 | 936 | -14/14 | 931 | -16/21 | 940 | -22/22 |
| SDXL | 916 | -13/14 | 918 | -18/18 | 918 | -21/20 |
MixEval-X Text2Video Leaderboard
Open-Source
Proprietary
| Text2Video Elo 🥇 |
95% CI | Text2Video Elo (1st Turn) 🥇 |
95% CI (1st Turn) | Text2Video Elo (2nd Turn) 🥇 |
95% CI (2nd Turn) | |
| HotShot-XL | 1024 | -8/10 | 1024 | -12/14 | 1025 | -12/11 |
| CogVideoX-5B | 1014 | -10/8 | 1020 | -14/12 | 1008 | -11/14 |
| LaVie | 1013 | -9/10 | 1009 | -14/12 | 1017 | -11/14 |
| VideoCrafter2 | 996 | -9/8 | 1002 | -14/12 | 990 | -13/10 |
| ModelScope | 995 | -9/9 | 987 | -13/13 | 1004 | -16/11 |
| ZeroScope V2 | 984 | -10/11 | 972 | -11/10 | 998 | -14/14 |
| Show-1 | 970 | -7/8 | 983 | -12/12 | 955 | -13/12 |
MixEval-X Text2Audio Leaderboard
Open-Source
Proprietary
| Text2Audio Elo 🥇 |
95% CI | Text2Audio Elo (1st Turn) 🥇 |
95% CI (1st Turn) | Text2Audio Elo (2nd Turn) 🥇 |
95% CI (2nd Turn) | |
| AudioLDM 2 | 1034 | -14/18 | 1036 | -19/19 | 1036 | -19/19 |
| Make-An-Audio 2 | 1019 | -14/16 | 1023 | -19/23 | 1012 | -20/32 |
| Stable Audio | 1019 | -14/14 | 1023 | -17/22 | 1018 | -23/19 |
| Tango 2 | 1010 | -16/16 | 995 | -27/17 | 1025 | -27/18 |
| ConsistencyTTA | 1005 | -17/15 | 1005 | -24/24 | 1006 | -22/26 |
| AudioGen | 982 | -13/14 | 978 | -16/23 | 985 | -22/22 |
| Magnet | 926 | -14/16 | 939 | -20/28 | 912 | -16/23 |